
When reading Designing Data-Intensive Applications, I was intrigued by the brief mention of Conflict-free replicated Datatypes, or CRDTs. These data structures can be copied to many computers in a network, where they undergo concurrent modification, and later be merged back together into a result that accurately reflects all of those concurrent modifications. The simplest such type is an incrementing counter, but there exist CRDTs for more complicated structures like lists and maps.
This reminded me of an interesting problem I worked on long ago. Abstractly, the problem was to allow concurrent edits to an ordered list in an environment where the computers making those changes were sometimes disconnected from the network, making coordination impossible. We came up with a solution, but didn't really have a name for it. I've long wondered whether or not there existed any well-known solutions to this problem.
It turns out that our solution was actually a "Sequence CRDT". These CRDTs are a topic of active research and have applications in collaborative document editing. If you can allow distributed edits to a sequence of characters, then you've solved one of the hairier problems of building a "Google Docs"-like collaborative editor.
Now that I know where to look, I can compare our approach to more well-known academic solutions to the same problem.
Introductions
All three of the solutions I'll be discussing have certain ideas in common.
Every scheme involves some sort of "position identifier" to represent a single element's position within a sequence. These identifiers must be unique and densely ordered.
Somewhat informally, given two positions $x$ and $y$ representing the positions of two elements in some sequence, then:
- $x \neq y$ (uniquness); and
- assuming $x < y$, there exists some $z$ where $x < z < y$ (density).
The use of position identifiers allows the position of an element can be specified entirely within the element itself, thus avoid many of the perils of conflicting changes being made without coordination.
If we had used a linked list structure, tracking successors or predecessor to define the sequence ordering, we might find ourselves in trouble if that predecessor or successor had been moved by another agent while we made an offline change.
If we had used a non-dense set of identifiers, like the set of integers, we might eventually find ourselves with $x$ and $y$ having values 23 and 24 respectively, and we would be unable to find any integer value between them.
If we have density but lack uniqueness guarantees, it's possible that user A and user B take similar actions at the same time that create positions $x$ and $y$ where $x = y$, but then you have the uncomfortable fact that there is no $z$ where $x < z < y$.
With these constraints in place, it is possible to write functions that generate positions for inserting elements between any two existing elements within the list. These new elements can be merged into other replicas of the sequence that may have undergone different modifications, and their relative positioning will remain unchanged.
Logoot
The paper introducing Logoot[1] includes a good explanation of the underlying theory and the applications to collaborative document editing. My description of it will involve lots of non-rigorous hand-waving, so please refer to the paper if you want a more complete explanation.
In Logoot, the position consists of a list of (Integer, SiteId) tuples. The integer values are chosen for sequence ordering purposes, while the SiteId ensures that every position value is unique.
For example, we might have positions $x$ and $y$ that look like this:
$$
x=[(10,s_1),(5,s_2),(7,s_3)]
$$
$$
y = [(10, s_4), (6, s_6)]
$$
(where $s_n$ is some arbitrary site identifier)
Comparison of position identifiers is implemented by comparing the integer values at each position in the list from left to right. The SiteId values are used as a tie-breaker if the integer values are equal. The SiteId is generated when the element is created by combining a client-specific unique identifier and a client-local logical clock that is incremented with every new position brought into existence on that client, which guarantees no two SiteId values will ever be equal.
If we wanted to insert a position z between the two positions, it might look something like this:
$$
z = [(10, s_7), (5, s_8), (3, s_9)]
$$
(the last element could be omitted if $s_8 > s_2$, but this choice of $z$ works for any choice of $s_8$ and $s_2$.)
This is one of many possible $z$ values. It turns out that the algorithm used to choose among the many possible in-between values can have a big impact on performance. If the choice is made poorly, or a worst-case scenario is encountered, the length of these lists can grow without bound.
That problem forms the motivation for looking at the next algorithm.
LSEQ
The LSEQ paper[2] includes a thorough discussion of allocation strategies and their consequences.
It refers to one of the allocation strategies recommended by the Logoot paper as the "boundary" allocation strategy, in that tended to stick to the "leftward" edge of possible position choices. That strategy is very effective when new elements are generally inserted at the end of the sequence, as is typical in document editing. But it performs poorly when new elements are added to the beginning of the sequence.
LSEQ uses two allocation strategies: "boundary+" and "boundary-". The former is a re-branding of Logoot's original "boundary" strategy and the latter is its opposite. The former favors right-insertion and the latter favors left-insertion.
LSEQ also introduces the concept of different "bases" at each level of the list. Logoot uniformly used "Integers" in its list elements (presumably meaning uint32_t or uint64_t). LSEQ doubles the available position-space with every list element. So one could have the first element in the range (0..8), the second in range (0..16), third in range (0..32), and so on.
This is combined with the clever idea of selecting different allocation strategies at each level. This ensures that, even if a particular edit-pattern is a worst-case at one level, the position IDs being created by that pattern will soon overflow to the next level, where that same editing pattern may well be a best-case scenario.
The paper ends with some benchmarks on real-world data (Wikpedia edits) that confirm this strategy does in fact perform better than Logoot in many cases.
UniquePositions
UniquePositions are a completely different implementation of the sequence CRDT concept.
The position identifiers are intended to be stored and compared as C strings. This has the benefit of making them compatible with existing systems that may not support more complex comparison algorithms. And since strcmp(3) is highly optimized on most systems, it's likely the comparison will be reasonably fast, too.
The uniqueness comes from a guaranteed-unique suffix that forms the last 28 bytes of the string. These are generated when the position identifier first comes into existence and depend on a large number of random bits to ensure uniqueness.
The algorithm for inserting between two existing positions is rather convoluted because of the complexity of keeping that unique suffix around while also trying to minimize ID growth.
All of this adds up to an algorithm that's kind of similar in behavior to Logoot, in that it suffers from unbounded identifier growth. We'll deal with that in the next section.
Compressing UniquePositions
If we look at the positions that result from worst-case edit patterns, we see what looks like a compression problem. The strings tend to grow to have large prefixes of 0xff, 0xff, 0xff, ... or 0x00, 0x00, 0x00, .. depending on whether the insertion is repeated on the right or left. This suggests that some form of run-length encoding might be appropriate.
So we start with textbook run-length encoding. When we see more than four characters of the same value x and certain alignment criteria are met, we can encode them as [x, x, x, x] ++ <32-bit big-endian count of x>. This is a wasteful encoding if there are only 4-7 of these characters present; but it's quite effective at compressing long runs of repeated characters up to 2^32 characters long.
But this means we'd lose the nice property we had earlier where our comparison function was simple string comparison. What we'd like is some compression function C that comes with a guarantee that x < y implies C(x) < C(y).
Taking some key ideas from a paper called "Order-Preserving Key Compression"[3], we allow two different ways to encode the same count. Rather than having a simple 32-bit unsigned count, we allow counts up to 31-bits to be encoded either as c, the count itself, or 2^32 - c. For decompression purposes either encoding represents the same count.
The choice of encoding is not arbitrary. It is chosen to ensure the compressed strings have the same sort-ordering as their uncompressed equivalents. From the source code:
When producing a repeated character block, the count encoding must be chosen in such a way that the sort ordering is maintained. The choice is best illustrated by way of example:
When comparing two strings, the first of which begins with of 8 instances of the letter 'B' and the second with 10 instances of the letter 'B', which of the two should compare lower? The result depends on the 9th character of the first string, since it will be compared against the 9th 'B' in the second string. If that character is an 'A', then the first string will compare lower. If it is a 'C', then the first string will compare higher.
The key insight is that the comparison value of a repeated character block depends on the value of the character that follows it. If the character follows the repeated character has a value greater than the repeated character itself, then a shorter run length should translate to a higher comparison value. Therefore, we encode its count using the low encoding. Similarly, if the following character is lower, we use the high encoding.
In the end, we get the desired shortening of long-repeated strings of 0xffs caused by right-insertion and 0x00s caused by left-insertion.
Charts and Conclusions
I built some micro-benchmarks so I could test out UniquePosition against Logoot and LSEQ. Here is
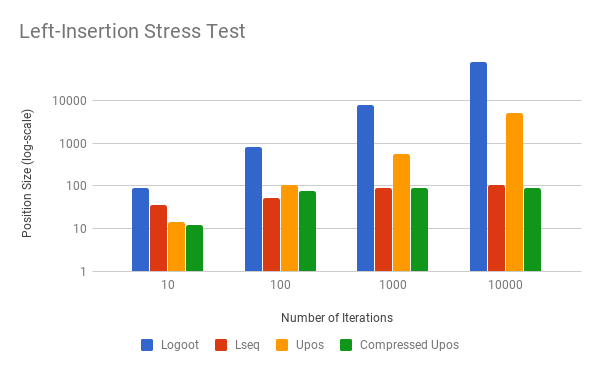
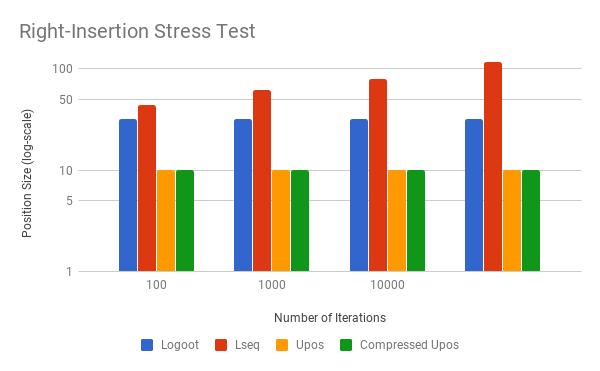
The uncompressed variants of UniquePosition grow almost as quickly as Logoot, which is not good. Those 10KB position identifiers would be likely to create challenges for any normal use case. But we can also see that LSEQ and compresed unique positions both do a very good job of keeping the identifier size growth under control.
That said, I would definitely prefer LSEQ to UniquePosition in new projects. The current implementation of unique positions requires decompressed positions when performing inserts. Although it's only temporary, the additional allocations and O(n) comparisons performed on these long positions would be rather expensive. LSEQ has no such problem.
References
https://hal.inria.fr/inria-00432368 "Stéphane Weiss, Pascal Urso, Pascal Molli. Logoot: A Scalable Optimistic Replication Algorithm for Collaborative Editing on P2P Networks. 29th IEEE International Conference on Distributed Computing Systems - ICDCS 2009, Jun 2009, Montreal, Canada. IEEE, pp.404-412, 2009, 2009 29th IEEE International Conference on Distributed Computing Systems. < http://www.computer.org/portal/web/csdl/doi/10.1109/ICDCS.2009.75 > < 10.1109/ICDCS.2009.75 > < inria-00432368 > ↩︎
https://hal.archives-ouvertes.fr/hal-00921633 "Brice Nédelec, Pascal Molli, Achour Mostefaoui, Emmanuel Desmontils. LSEQ: an Adaptive Structure for Sequences in Distributed Collaborative Editing. 13th ACM Symposium on Document Engineering (DocEng), Sep 2013, Florence, Italy. pp.37–46, 2013, < 10.1145/2494266.2494278 >. < hal-00921633 >" ↩︎
http://bitsavers.trailing-edge.com/pdf/dec/tech_reports/CRL-94-3.pdf "Gennady Antoshenkov, David B. Lomet, and James Murray. 1996. Order Preserving Compression. In Proceedings of the Twelfth International Conference on Data Engineering (ICDE '96), Stanley Y. W. Su (Ed.). IEEE Computer Society, Washington, DC, USA, 655-663. " ↩︎